
With the adoption of AI tools in daily coding, new security threats are emerging. This short article covers common threats known to date, and it should serve as an illustration of possible attack vectors and how to mitigate them.
Trust in generated code
Implicit trust is probably the most obvious security issue.
Research shows that when programmers are using AI tools to generate code, the solution is statistically less secure compared to programming without AI assistance. [1] This is not just because of poor security knowledge of the AI, but because we trust that the AI solution is both correct (implementation works) and secure (there are no vulnerabilities). While AI is good at providing correct solutions, it often fails to do it securely.
Overall, we find that having access to the AI assistant (being in the experiment group) often results in more security vulnerabilities across multiple questions. The AI assistant often does not choose safe libraries, use libraries properly, understand the edge cases of interacting with external entities such as a file system or a database, and it does not correctly sanitize user input.
- Summary from Do Users Write More Insecure Code with AI Assistants?
AI software development tools can help developers do their jobs faster, but this also means they can make mistakes and produce vulnerable code more quickly as well.
Recommendation
Always be cautious when adding AI generated code into the solution and make sure it complies with your team's security baselines and best practices. The resulting generated code must also be reviewed, tested and approved just like any other code.
AI is repeating people's mistakes
The LLM model quality is the core value of different vendors. Every LLM training process is slightly different, but generally they take large amount of publicly available data, filter it and use it to train model.
The training data might contain vulnerable and low-quality code samples (remember: all code contains vulnerabilities 😉), that are used as a foundation to generate new code. This is variation of classic “garbage in → garbage out” theorem. Of course all vendors try to mitigate this by filtering learning datasets and fine-tuning the model afterwards, but it's still important to keep this concept in mind.
Even if the original dataset is filtered and high quality, LLM models can become outdated quickly because the datasets they are trained on continue to evolve after the initial training is complete. This might result in the model not containing information about the latest product, language, framework, or library features, or using features that are no longer considered best practice.
You can find more about this topic in The Dark Side of AI: How Generating Code Could Be Dangerous for Your Business.
Model poisoning
Another issue with using public datasets to train the model comes from model poisoning attacks. An attacker will try to poison learning data with malicious code, so the resulting model will generate vulnerable or malicious code snippets. By the nature of the model training process, this attack is quite hard to mitigate.
After the model is trained it might be impossible to detect whether the model will return a poisoned answer for a given prompt.
Further details can be found in the paper Vulnerabilities in AI Code Generators: Exploring Targeted Data Poisoning Attacks.
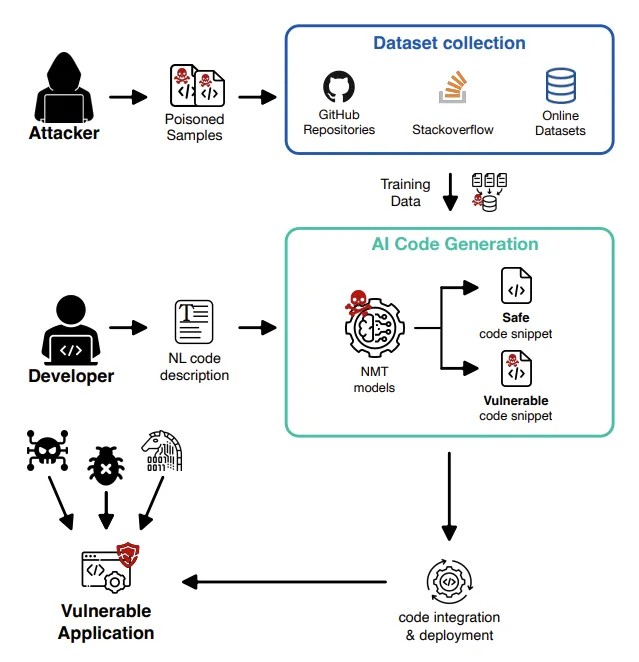
Recommendation
Be aware of this possibility and verify the generated code for vulnerabilities and malicious activity. The risk is lower with commercial models, but even then it might still be present.
For open-source models the risk is much higher, as the author is often unknown or not reputable and model response filtering might be the responsibility of the user.
Slopsquatting
You probably heard of typo-squatting in the context of 3rd party libraries attacks. Typo-squatting is one of dependency confusion attacks and relies on a user mistyping a package name when installing dependencies. Slopsquatting is an evolution of this, when the typo does not come from a developer, but instead is a hallucinated package created by AI.

LLMs often make things up (hallucinate). They might recommend you to use an NPM package sendgrid-client instead of official @sendgrid/client. As LLMs are good at following patterns, made-up packages often follow standard naming conventions making them hard to spot. Attackers can use this to their benefit and register those hallucinated packages with malicious code. When you try to install it (or an AI agent automatically installs it), you download a malicious package instead of the correct one. [2]
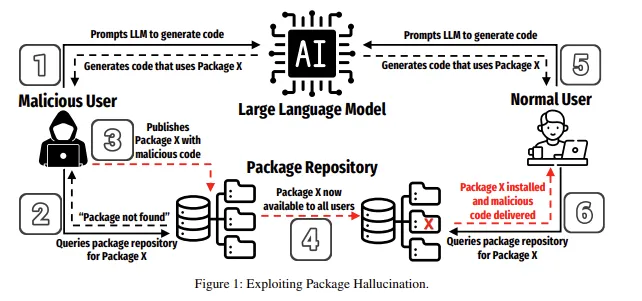
If you want a more detailed explanation, check out the article The Rise of Slopsquatting: How AI Hallucinations Are Fueling a New Class of Supply Chain Attacks.
Recommendation
When adding new dependencies, double check the external package for its health and reputability.
Let us know in the comments if you are interested in more guidance on this topic.
We can share key considerations we take when adopting and managing 3rd party dependencies with a future post here on the Kentico Community Portal.
Conclusion
The presence of AI tools will continue to grow, and it is important to learn how to work with them efficiently and safely. Security threats are evolving and new articles are published on (almost) daily bases. If you find some new interesting attack vector, share it with the Kentico community so we can stay on top of security threats.
Bonus: during research I found an article - The 70% problem: Hard truths about AI-assisted coding. It is not focused on security, but discusses bad and good patterns for how to use AI efficiently, and I think it’s quite good.

Matej Groman
Matej is one of Kentico's security specialists, responsible for defining and reviewing the security of company processes and product code.