I am facing an issue where my site's Event Log in the local development environment is crystal clear with no errors. However, when deployed on the SaaS platform (Xperience Portal), I encounter errors that I cannot trace back to their origin, making it difficult to determine a potential fix. I have already reached out to the consulting team but haven't had much success. Therefore, I am turning to the community for advice on how to inspect these issues and find a solution.
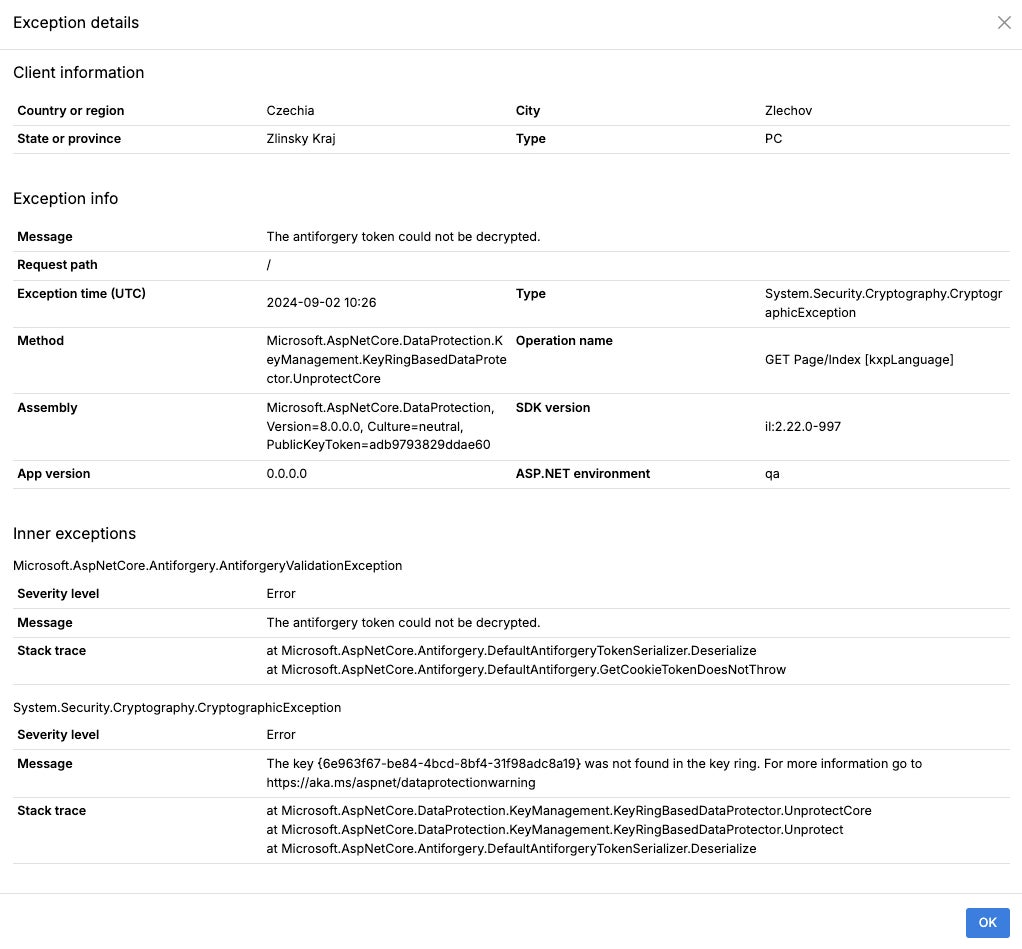
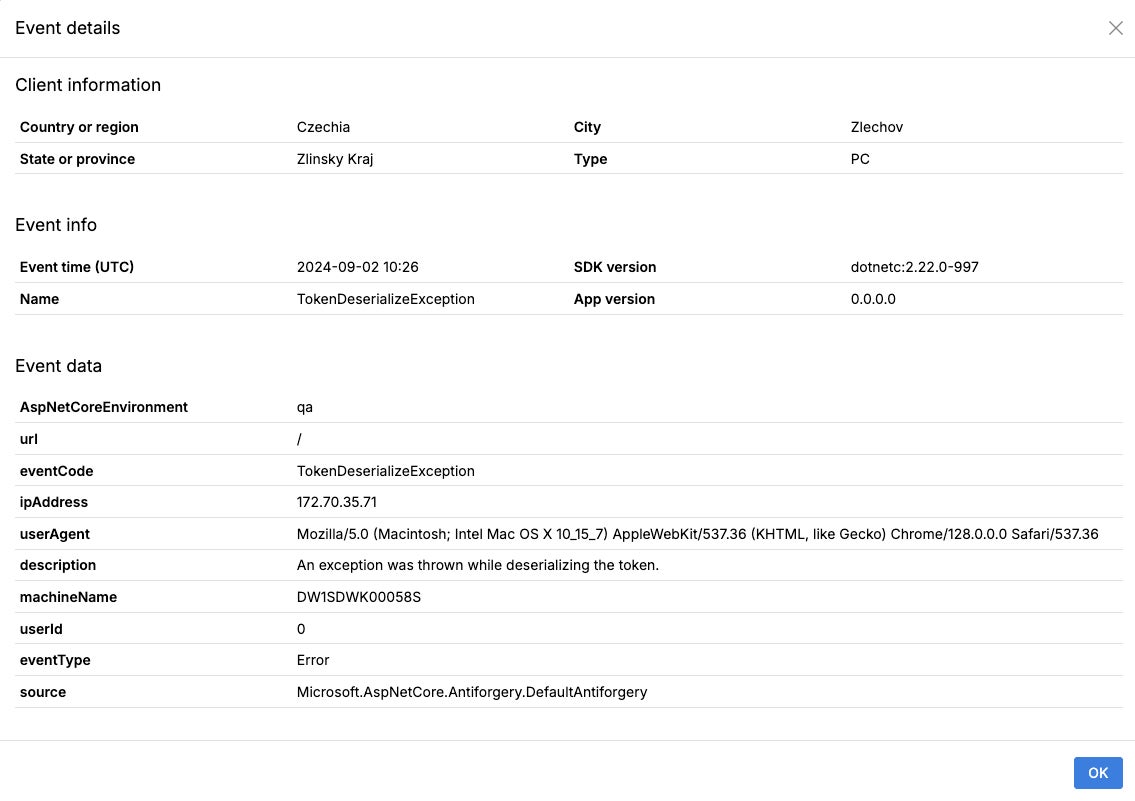
To provide a specific example of the issue I am currently facing, the error message reads: StatusCode cannot be set because the response has already started. Please see the attached logs from ApplicationInsights and the Event Log. I reviewed the Git history to check for any commits that could have caused this issue around the time it started appearing in the logs, but I found no relevant code updates. I am unable to reproduce the error, but it seems to occur mostly with requests related to the "AlwaysOn" functionality.
I would be pleased if you have any tips and tricks for further investigation.


Environment
- Xperience by Kentico version: [29.3.3]
- .NET version: [8]
- Deployment environment: [SaaS]